평가위원 추천 시스템

빅데이터 기술 기반 평가위원후보 자동추천시스템 모듈
연구 기간 : 2016년도 개발시작 2017년 종료
적용 대상 : IITP > RISS
빅데이터 분석기법을 활용해 평가 대상과제와 가장 기술 상관성이 높은 정보〃 경력 등을 보유한 최적 평가위원 후보를 자동 추천하는 식이다.
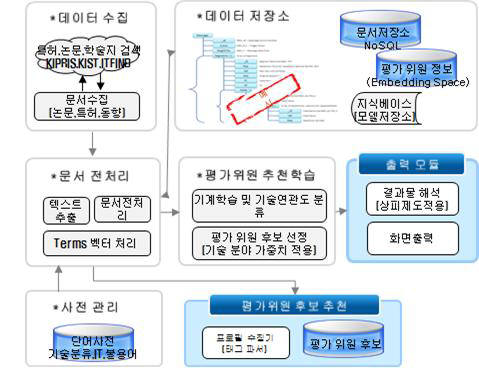
시스템 화면 구성
전문가 추천 시스템 연구
서론
2015년 사업관리 시스템 개발의 일환으로 빅데이터 업무중 평가위원 추천 시스템과 과제 중복성 검사기 시스템을 납품하였다. 텍스트 마이닝 기술을 기반으로 진보된 딥러닝 알고리즘을 사용하여 평가위원이 가지고 있는 기술성을 평가하고 평가위원의 부적절한 관계를 검증하는 시스템이다. 본 사업의 추진 방향은 첫 사업 완료 이후 시스템 유지 보수를 하며 알고리즘을 개선하고 평가위원의 기술을 검증하며 더 많은 평가위원을 확보하는 것이였다. 하지만 실 사용자의 요구 분석 과정과 데이터 분석과정 없이 단기로 개발을 진행 결과 서비스 상의 문제점이 발생하였다. 이의 문제점을 분석하고 개선 방향을 도출하는 방향으로 진행한다.
추천 시스템 문제점 분석
전문성 자료가 정상이 아니였다.
평가위원이 입력한 자료가 10% 미만의 내용만 실제 데이터로 확인 되었다.
특허가 본인의 것이 아니며 신청만 한 상태거나 특허가 아닌 상품등록도 있었다.
논문의 경우도 다수가 확인이 안됐다. 특히 해외 논문의 경우 99%에 가까웠고 번역된 제목이 틀리거나 오래된 학술지 내용이거나 본인이 제1저자가 아닌 경우도 다수 있었다.
연령이 70세 이상 고령인 분들도 다수 있으며 전산화 이전 자료라 이미지 스캔본이 많고 현 시대에 적용 가능한 기술성을 가지고 있다고 판단하기에는 의심의 여지가 있다.
데이터 정제 작업이 없었다.
추천기 또한 기본 기능은 자료 검색으로부터 시작한다. 오라클 같은 RDB 하고 틀린점은 그래프 탐색 쿼리나 텍스트 연관 검색을 사용하는 것이다. 검색 대상이 될 자료는 앞에서 제기한 평가위원의 자료나 제안서들이다. 이들 자료를 1차 가공해서 사용할수 있는 데이터 형태로 정제를 해야 한다. 가공을 하기 위해서는 일정한 형태로 내용 정리가 우선이다.
내용 분석 대상이 IT 관련만이 아니였다.
ICT 융복합은 총 180개 분야이며 전체 산업 분류 총 419개가 존재한다. ICT 분야도 IT라는 것을 제외하면 50% 이상이 IT 와는 거리가 먼 내용들이다. 예를 들어 “농업 ICT” -> “농업”
초기 학습 내용을 IT 분야로 한정을 했었기 때문에 IT를 제외한 분야에서는 추천 결과가 엉뚱한 오류가 다수 발생하였다.
과제 제안서에는 사업 관련된 내용을 추출하는데 문제점이 있다.
R&D 제안서는 문서의 80%가 연구 목적과는 상관없는 내용들로 구성된다. 연차 보고서의 경우 제목을 제외한 99%가 무관하다. 일반 시스템 개발 제안서의 경우에도 도식과 그림을 제외하고 90% 정도가 사업과 관련이 없는 내용이다. 대학 R&D 연구 제안서의 경우 대부분의 내용이 인력 운용에 관련이다.
알고리즘의 문제점
사용된 가장 중요한 알고리즘으로 LF-LDA은 경우 다중 주제 분류이다.
여러 개의 주제가 틀린 제안서를 한통에 분석하기에는 가장 최적합 알고리즘이다.
그러나 분석 대상의 문서 종류가 어떤것이냐에 따라 Overt fitting 문제가 발생한다.
앞선 문제점인 핵심 내용 추출에서 사업 운용과 금전에 관한 내용이 대 다수 차지하다 보니 분석의 주된 주제는 금융과 사업운용으로 나오게 된다.
사용자의 요구사항을 분석하지 않았다.
실제로 평가위원으로 활동중인 사람은 전체 등록된 평가위원의 1% 정도이다.
그 중 절반이 네트워크 전문가이고 나머지 대부분이 IT 계열 종사자들이다.
세분류에서는 한 분야에서만 전문가가 아니다. 오랜 시간 연구 활동을 해왔기 때문에 참여한 사업의 성격에 따라 다중 전문가 이며 다수의 참여 논문과 특허를 보유하고 있다.
ICT분야도 180개 이지만 유사분야를 정리하면 120개 정도이다.
실제 사업화로 기획된 분야만 추려내면 더 줄어들 것이다.
결론적으로 한정된 인원과 분야에 대해 평가위원의 기술성 분류를 하기위해 평가위원 전체를 클러스터링을 할 필요는 없었다. 오히려 정확도를 떨구는 요인이 된다.
문제점 개선 방향
3.1 전문가 자료의 정합성 검증
전문가의 기술 자료로 논문/특허 검증된 자료만을 사용하도록 하며 논문의 경우 DOI 에 등록된것만 사용하며 저자는 제1저자인 경우만 해당하도록 하며 가중치는 논문 영향지수를 사용하도록 해야 한다. 특허와 논문 가중치 비율은 5:1 정도 하도록 한다. 특허의 비율은 논문의 비율에 비해 1:10 정도이다.
3.2 자료 색인 과정
평가위원을 전문 자료를 전처리하는 단계가 필요하다.
형태소 분석기와 NER 추출기를 적절히 조합하여 XML 색인 자료를 만드는 과정으로,
“간이 지식 베이스” Simple Knowledge base를 구성이며 Apache Jena 와 SparQL을 사용하도록 한다.
예를 들어 “오바마는 미국의 대통령이다.” 라는 문장을 분석해서 색인한 내용은 다음과 같이 구성된다.
“<element:person:name>오바마</element>는 <element:nation>미국</element>의 <element:position>대통령</element>이다.
이를 위해서는 먼저 element 요소의 정의된 XML 사전이 필요하다. XMLSpy 같은 XML 도구를 사용할수 있다.
NLP2RDF 포맷 변환
Simple Knowledge base 데이터 형태의 LOD데이터 구조
3.3 IT와 상관없는 다양한 분야의 자료를 학습시킨다.
주요 기술 정보는 IT관련된 자료를 중심으로 한다. IT와는 관련 없는 정보들은 Word2Vec 학습용 자료로 추가하도록 한다. 수집 자료는 Naver 뉴스나 소설책 등 한국어학회에서 제공하는 말뭉치 글들을 사용한다. 특허 15만건과 뉴스 1000만건 자료를 Word2Vec 학습 시키도록 한다.
IT용어에는 왕과 여왕 관계가 아래와 같이 나오지 않는다. Ex> 삼성->왕
3.4 과제 제안서의 내용 추출
과제 제안서에서 내용을 추출하기 위해 과도한 Stopword 를 적용한 결과 반드시 있어야 할 내용도 같이 생략되는 문제가 있었다. 이미 1차로 정리된 내용 요약본과 지정된 키워드만을 사용하도록 한다. 그리고 분야 한정으로 과제 분류 산업분류를 사용하도록 한다.
3.5 분류 알고리즘이 1차 알고리즘으로 사용
가장 빠르고 적은 학습에서도 높은 정확도를 보여주는 Naïve baysian 알고리즘을 1차로 사용하여 산업 분류를 하도록 한다. ICT 융복합이기 때문에 세분류까지는 아니더라도 2차 분류까지는 범위를 한정해서 검색하기 위한것이다.
(평가 분과 분야 * n분류 가중치)를 해당 분야 가중치로 사용하도록 한다.
또한 LDA 알고리즘의 문제점으로 Over fiting 문제점은 지난 AI 대회에서 사용한 LDA-KNN 기법을 적용하여 주제 분류 정확도를 0.6 에서 0.74 로 높일수 있다.
주제 분류도 이미 ICT 분야 120개로 정해저 있기 때문에 hybrid supervised clusting 기법으로,
LF-LDA 에 다중 레이블 분류 기법을 적용한
NB-LFLDA-KNN 알고리즘을 개발하면 정확도를 높일수 있을것으로 기대하고 있다.
이미 기존 “스마트 특허 검색기”를 연구용으로 제작하면서 다중 분류의 가능성은 테스트해본 상태이다. “바람이 분다” 에 대한 IPC 다중 분류 결과

3.6 사용자의 분석 결과에 대한 이해와 수동 조작 기능이 필요하다.
사업의 목표와 사업에 해당하는 내용과 틀린 경우가 발생한다.
예로 평가 분과는 보안 관련이지만 제안 요청서는 네트워크 관련된 내용이다.
자동 분석보다는 담당자가 수동으로 분야를 선택해서 해당 분야 전문가를 점수로 평가해 고를수 있게 해야 한다.
사용성에 있어 분석 시간의 15분 소요되는데 이들에게 30초 이상 넘어가는 서비스 페이지는 실패한 것으로 봐야 한다.
분석 대상 인원수가 한정되어 있고 분류가 정해져 있으면 큰 카테고리 분류에서 내용 전문가 내용 유사도 (0-1) 값 보다는 절대 수치 형태인 유클리드 거리 비교가 더 유효할 것이다.
연구 목표
Hyrid Naïve baysian + LF-LDA 알고리즘 개발
반 지도 학습 방법으로 문서 특징을 Naïve baysian에서 가져다가 LDA 알고리즘에 사용하는 알고리즘을 개발한다.
대표적인 지도 학습방법으로 Naïve baysian에 오버 피팅을 방지하고자 개선된 Multnomial 방식을 사용한다.
케글 실험에서 5개 종류의 뉴스 316814 학습에 105605개의 테스트시 92% 정확도를 보이고 있다.
LDA 분석 단계로 1차 분류 한정된 데이터를 가지고 클러스터링을 진행한다.
진행된 결과는 문서 세분류 데이터로 AUROC 값으로 측정하도록 한다.
4.2 ICT 산업분류-특허(IPC) 자동 연계 모델
ICT 사업 성과물을 대상으로 제출된 특허를 대상으로 특허 IPC 다중 분류 모델을 구성한다.
NLP2RDF 시스템 구축
지식 베이스 정보로 활용 가능한 LOD 데이터를 변환하는 시스템을 구축한다.
NLP2RDF 의 일부 기능만을 사용하기 때문에 한글 NLP, Restful service 와 Jena를 활용하여 문서 변환/저장/검색 기능으로만 사용하도록 구성한다.
참고 논문
LOD2Korea https://nanopdf.com/download/nlp2rdf-swrc_pdf
한국어 NLP2RDF 프레임워크 http://semanticweb.kaist.ac.kr/home/images/2/25/한국어_자연어처리리의_NIF_적용.pdf